
ハルビン工業大学(深圳)• 2024 • オペレーティングシステム Lab• における解決策 • HITSZ 操作系统实验 2024
当サイト内のコンテンツの無断転載、引用、コピーは禁止されています。
Lab 1 Utils
一、次の質問を答えてなさい
1. sleep.cについての質問
2. パイプについての質問
二. コードデザイン
(1) pingpong のデザイン
パイプの作成
🌟 パイプの宣言:
int pipe_parent_to_child[2], pipe_child_to_parent[2];2 つのパイプを定義しました。それぞれ親プロセスから子プロセスへの通信(pipe_parent_to_child)と子プロセスから親プロセスへの通信(pipe_child_to_parent)に使用されます。
🌟 パイプの初期化:
pipe(pipe_parent_to_child);
pipe(pipe_child_to_parent);pipe システムコールを使用してパイプを作成します。各パイプには 2 つのディスクリプタがあります: [0] は読み取り端、[1] は書き込み端です。
データの送受信
🌟 子プロセスの作成:
int pid = fork();fork() システムコールを使用して子プロセスを作成します。fork() の戻り値が 0 の場合、現在は子プロセス内で実行中であり、正の値の場合は親プロセス内であることを意味します。
🌟 子プロセス:
if (pid == 0) {
close(pipe_parent_to_child[1]); // Close Write End
read(pipe_parent_to_child[0], buffer, MAXLEN);
printf("%d: received %s from pid %d\n", getpid(), buffer, parent_pid);
close(pipe_parent_to_child[0]); // Close Read End
close(pipe_child_to_parent[0]);
write(pipe_child_to_parent[1], "pong", 5);
close(pipe_child_to_parent[1]);
}- 親プロセスから子プロセスにメッセージを送信する際、子プロセスはパイプの書き込み端を閉じ、読み取り端だけを保持して親プロセスからデータを受信します。
- その後、
read()を使用してパイプからデータをバッファに読み込み、親プロセスから受信したメッセージを表示します。 - 子プロセスの PID は
getpid()を使用して取得します。一方、親プロセスの PID はmain関数の冒頭でgetpid()を用いて取得し、parent_pid変数に格納されており、両プロセスで共有されます。 - メッセージを処理した後、子プロセスは読み取り端を閉じ、次に
write()を使用して親プロセスにデータを送信します。
🌟 親プロセス:
else {
close(pipe_parent_to_child[0]); // Close Read End
write(pipe_parent_to_child[1], "ping", 5);
close(pipe_parent_to_child[1]); // Close Write End
close(pipe_child_to_parent[1]);
read(pipe_child_to_parent[0], buffer, MAXLEN);
printf("%d: received %s from pid %d\n", getpid(), buffer, pid);
close(pipe_child_to_parent[0]);
}- 親プロセスはパイプの読み取り端を閉じ、
write()を用いて子プロセスにデータを送信します。送信が完了した後、書き込み端を閉じます。 - その後、
read()を使用して子プロセスからデータを受信し、内容を表示します。親プロセスの PID はgetpid()で取得可能であり、子プロセスの PID はfork()の戻り値をpid変数に保存して利用します。
(2) find のデザイン
- 背景:
lsコマンドの機能は、指定されたパス内のファイルやフォルダ情報を取得することです。このため、findコマンドの設計では、lsの実装を参考にしました。つまり、指定されたパス内のファイルやフォルダ情報を取得する機能が既に実装されているものと見なします。 - find の基本動作:
findコマンドの核心は、指定された名前と同じファイルまたはディレクトリを見つけることです。これにはstrcmpを用いた文字列比較を使用します。一致した場合は、該当するパスを出力します。 - ディレクトリの再帰検索:
検索中にディレクトリを見つけた場合、そのディレクトリに対して再帰的に検索を実行します。ただし、.と..は検索対象外とします。この再帰操作では、再帰前のディレクトリとディレクトリ名を結合して次の入力パスを作成し、ファイル名は変更しません。 - 重複検索の排除:
switch (st.type)の中で、case T_DIRのみを残しました。これは、case T_DIR内でファイルの位置を特定できるため、case T_FILEを特別に処理する必要がないからです。 - 重要なコード部分:
//FIND IMPLEMENTATION
if (strcmp(de.name, name) == 0)
printf("%s\n", buf); //Print the result from (result).
/*Recursive 'find' in sub-directory,
mind that . and .. should not be considered as sub-directory */
if (st.type == T_DIR && strcmp(de.name, ".")!=0 && strcmp(de.name, "..")!=0)
find(buf, name); //Start 'find' from the 'buf' just updated before
//FIND END(3) xv6 起動プロセスの分析
commands.gdb ファイルには、initcode と init プログラムの名前を出力するための GDB コマンドが記述されています。この実験要件を満たすには、以下の 6 行のコマンドだけで十分です:
(gdb_cmd_dump)
### proc 構造体の 'name' フィールドが変更される直前にブレークポイントを設定
tbreak kernel/exec.c:90
### init プログラムを準備し、qemu をブレークポイントまで実行
continue
### この時点では 'proc' はまだ変更されておらず、'name' フィールドを出力
print cpus[$tp]->proc->name
### 'safestrcpy()' を実行して 'proc' の 'name' フィールドを変更
next
### この時点で 'proc' が変更され、'name' フィールドを再度出力
print cpus[$tp]->proc->name
### ダッシュボードをリフレッシュ
dashboard 明らかに、後半の 5 行のコマンドは出力ロジックに必要不可欠です。6 行で要件を満たすには、ブレークポイントを 1 つだけ設定する必要があります。ポイントは、proc 構造体の name フィールドが変更される瞬間を正確に特定し、そのタイミングでブレークポイントを設定することです。
ブレークポイントで対応するコードの実行前に 1 回出力し、実行後にもう 1 回出力することで、要件を満たすことができます。
このブレークポイントtbreakに対応する文は、safestrcpy(p->name, last, sizeof(p->name)) です。この文は、lastを p->name フィールドにコピーします(p は myproc() から取得され、現在のプログラムを示しています)。
分析の流れ
目的:initcode が init に切り替わる瞬間を特定し、さらに proc 構造体の name フィールドが変更される位置を見つけます。
xv6 の起動プロセスを解析:
起動時に、最初に userinit() 関数内で initcode をメモリにロードします。この関数ではプログラムのロードだけでなく、proc 構造体の各種パラメータも設定されます。その中には、プログラム名の設定を行う以下の呼び出しも含まれます:safestrcpy(p->name, "initcode", sizeof(p->name));
initcode から init への切り替え:
この切り替えは ECALL を通じて行われます。
initcode[] = {
...
0x93, 0x08, 0x70, 0x00, // LI a7, 7 0x00700893
0x73, 0x00, 0x00, 0x00, // ECALL 0x00000073
...
};
# exec(init, argv)
LA a0, init
LA a1, argv
LI a7, SYS_exec # LI a7, 7
ECALLその後、割り込みハンドラに入り、syscall に動作がディスパッチされます。syscall.cで確認できます:
num = p->trapframe->a7;
p->trapframe->a0 = syscalls[num](); a7 の値は 7 であり、syscalls[7] が指す関数が呼び出されます。マクロ syscall.h を参照すると、関数 extern uint64 sys_exec(void); を指していることがわかります。
sys_exec 関数の探索:
この関数を sysfile.c 内で確認すると、プログラムの実行操作がさらに exec 関数に割り当てられていることがわかります。
uint64 sys_exec(void) {
char path[MAXPATH], *argv[MAXARG];
int i;
uint64 uargv, uarg;
if (argstr(0, path, MAXPATH) < 0 || argaddr(1, &uargv) < 0) {
return -1;
}
memset(argv, 0, sizeof(argv));
for (i = 0;; i++) {
if (i >= NELEM(argv)) {
goto bad;
}
if (fetchaddr(uargv + sizeof(uint64) * i, (uint64 *)&uarg) < 0) {
goto bad;
}
if (uarg == 0) {
argv[i] = 0;
break;
}
argv[i] = kalloc();
if (argv[i] == 0) goto bad;
if (fetchstr(uarg, argv[i], PGSIZE) < 0) goto bad;
} int ret = exec(path, argv); for (i = 0; i < NELEM(argv) && argv[i] != 0; i++) kfree(argv[i]);
return ret;
bad:
for (i = 0; i < NELEM(argv) && argv[i] != 0; i++) kfree(argv[i]);
return -1;
}exec 関数の分析:exec.c 内でプログラムのロード操作が行われており、initcode プログラムのロード時と同様に、proc構造体の設定操作も行われています。ここから、initcode が init に切り替わる中心的な処理がこの関数内にあると判断できます。目標は proc の name フィールドが変更される瞬間を取得することなので、exec 内でその変更を行う文を特定します。
変更箇所の特定:
最終的に、以下の文が 90 行目にあることを発見しました:
safestrcpy(p->name, last, sizeof(p->name));この文が proc の name フィールドを変更しています。
Lab 2 Syscall
一、次の質問を答えてなさい
1. kernel/syscall.cのトラップ
関数syscall()がどのようにシステムコール番号に基づいて対応するシステムコールハンドラ(例: sys_fork)を呼び出すか説明してください。また、syscall()が具体的なシステムコールの戻り値をどこに保存するか教えてください。
static uint64 (*syscalls[])(void) = {
[SYS_fork] sys_fork, [SYS_exit] sys_exit, [SYS_wait] sys_wait, [SYS_pipe] sys_pipe,
[SYS_read] sys_read, [SYS_kill] sys_kill, [SYS_exec] sys_exec, [SYS_fstat] sys_fstat,
[SYS_chdir] sys_chdir, [SYS_dup] sys_dup, [SYS_getpid] sys_getpid, [SYS_sbrk] sys_sbrk,
[SYS_sleep] sys_sleep, [SYS_uptime] sys_uptime, [SYS_open] sys_open, [SYS_write] sys_write,
[SYS_mknod] sys_mknod, [SYS_unlink] sys_unlink, [SYS_link] sys_link, [SYS_mkdir] sys_mkdir,
[SYS_close] sys_close, [SYS_rename] sys_rename, [SYS_yield] sys_yield,
};
void syscall(void) {
int num;
struct proc *p = myproc();
num = p->trapframe->a7;
if (num > 0 && num < NELEM(syscalls) && syscalls[num]) {
p->trapframe->a0 = syscalls[num]();
} else {
printf("%d %s: unknown sys call %d\n", p->pid, p->name, num);
p->trapframe->a0 = -1;
}
}syscallsは関数ポインタ配列で、syscall.h内のマクロ定義された呼び出し番号をインデックスとして使用し、対応するシステムコール関数を指します。
例えばsys_forkの場合、ECALL命令が発生すると、syscall()関数はレジスタa7からシステムコール番号SYS_forkを取得します。syscall.hによると、SYS_forkは1に等しいことが分かります。
次に、コードの以下の部分p->trapframe->a0 = syscalls[num]();
では、syscalls[1]が指す関数がsys_forkです。その戻り値(uint64型)は現在のユーザープロセスの中断フレームのa0レジスタに保存されます。
2. kernel/syscall.cの引数渡す
どの関数がシステムコールの引数を渡すために使用されるか教えてください。また、argraw()関数の意味を説明してください。
argraw、argint、argaddr、argstr関数はシステムコール引数を渡すために使用されます。argraw関数は、ユーザープロセスの中断フレームの特定の引数レジスタ(a0~a5)の値をそのままuint64型として返します。
3. kernel/proc.cおよびproc.h
プロセスコントロールブロック(PCB)はどの配列に保存されていますか?PCB内のどのメンバーがプロセスの状態を示していますか?また、その状態は何種類ありますか?
プロセスコントロールブロックはグローバル配列procに保存されています。PCB内のstateメンバーがプロセスの状態を示しています。状態は以下の5種類です:
- UNUSED
- SLEEPING
- RUNNABLE
- RUNNING
- ZOMBIE
4. やかましい$記号
タスク1で、子プロセス(プロセス4、5、6)の出力の前に必ず$記号が表示されるのはなぜですか?(ヒント: shellプログラムsh.cはいつ$記号を出力しますか?)
//shell
$ exittest
[INFO] proc 3 exit, parent pid 2, name sh, state sleeping
[INFO] proc 3 exit, child 0, pid 4, name child0, state sleeping
[INFO] proc 3 exit, child 1, pid 5, name child1, state sleeping
[INFO] proc 3 exit, child 2, pid 6, name child2, state sleeping
$ [INFO] proc 5 exit, parent pid 1, name init, state runnable
[INFO] proc 4 exit, parent pid 1, name init, state runnable
[INFO] proc 6 exit, parent pid 1, name init, state running
コードsh.cを調べると、$記号はgetcmd()関数のみで出力されることが分かります。getcmd()関数はsh.c内で1回だけ呼び出されており、以下のようにwhileループで実行されるたびに$記号を出力します:while (getcmd(buf, sizeof(buf)) >= 0) { ... } exittestを読むと、親プロセス(exittest)は子プロセスが終了する前に既に終了しています。この情報はwait(0,0)によって捕捉され、新しいループに入ります。その結果、$記号が出力されます。次に、子プロセスがスリープ状態から復帰し、終了します。そのため、子プロセスが一括終了する前にターミナルには安定的に$記号が出力されます。
5. 乱れたyield出力
タスク3で、テスト時にCPUの数を1に指定する必要がある理由は何ですか?CPUの数が複数の場合、出力結果が乱れるのはなぜですか?(ヒント: マルチコアスケジューリングとシングルコアスケジューリングの違いを説明してください。)
プロセステーブルはグローバルであり、CPUコアの数に関わらず共有されます。プロセスはスピンロックを設定していますが、プロセステーブル自体にはロックが設定されていません。xv6のスケジューラでは、各CPUに独自のスケジューラが存在します。そのため、非常に短時間の間に複数のCPUが複数のRUNNABLE状態のプロセスを取得し、ほぼ同時に実行を開始します。この結果、コンソール出力が予測不可能な順序で行われ、出力が乱れます。
二. コードデザイン
(1) exitのデザイン
出力要件によると、以下の2種類の情報を出力する必要があります:
プロセス終了時にその親プロセスの情報。プロセス終了時にその子プロセスの情報。proc構造体を見ると、各プロセスの説明にはその親プロセスがparentフィールドに保存されていることが分かります。
// Per-process state
struct proc {
struct spinlock lock;
// p->lock must be held when using these:
enum procstate state; // Process state
struct proc *parent; // Parent process
//...
};そのため、1つ目の情報を出力する場合、プロセスが終了する際にexit()関数内でparentフィールドを取得して関連情報を出力すれば十分です。
//kernel/proc.c:exit(){...
// grab a copy of p->parent, to ensure that we unlock the same
// parent we locked. in case our parent gives us away to init while
// we're waiting for the parent lock. we may then race with an
// exiting parent, but the result will be a harmless spurious wakeup
// to a dead or wrong process; proc structs are never re-allocated
// as anything else.
acquire(&p->lock);
struct proc *original_parent = p->parent;
exit_info("proc %d exit, parent pid %d, name %s, state %s\n", p->pid, original_parent->pid, original_parent->name, stringstate(original_parent->state));
release(&p->lock);
//...また、プロセス状態を文字列に対応付けるため、以下のような関数stringstate()を設計しました:
char* stringstate(int state){
char* states[6]={"unused","sleeping","runnable","running","zombie","undefined"};
return states[state];
}2つ目の情報については、exit()関数内のreparent()関数を参照することで子プロセスの親プロセスが変更されるタイミングを特定できます。
// Pass p's abandoned children to init.
// Caller must hold p->lock.
void reparent(struct proc *p) {
struct proc *pp;
int child_num=0;
for (pp = proc; pp < &proc[NPROC]; pp++) {
// this code uses pp->parent without holding pp->lock.
// acquiring the lock first could cause a deadlock
// if pp or a child of pp were also in exit()
// and about to try to lock p.
if (pp->parent == p) {
// pp->parent can't change between the check and the acquire()
// because only the parent changes it, and we're the parent.
acquire(&pp->lock);
exit_info("proc %d exit, child %d, pid %d, name %s, state %s\n", p->pid, child_num++, pp->pid, pp->name, stringstate(pp->state));
pp->parent = initproc;
// we should wake up init here, but that would require
// initproc->lock, which would be a deadlock, since we hold
// the lock on one of init's children (pp). this is why
// exit() always wakes init (before acquiring any locks).
release(&pp->lock);
}
}
}このループ内で子プロセス情報を出力するだけです。自然に、子プロセスが終了する際には親プロセスがinitである情報が出力されます。
//shell
$ exittest
exit test
proc 3 exit, parent pid 2, name sh, state sleeping
proc 3 exit, child 0, pid 4, name child0, state sleeping
proc 3 exit, child 1, pid 5, name child1, state sleeping
proc 3 exit, child 2, pid 6, name child2, state sleeping
$ proc 4 exit, parent pid 1, name init, state runnable
proc 5 exit, parent pid 1, name init, state runnable
proc 6 exit, parent pid 1, name init, state running(2) waitのデザイン
最初にsysproc.cとdefs.hでwait関連のシステムコールを登録し、関連するパラメータを取得します。
//kernel/defs.h
int wait(uint64, int);
//kernel/sysproc.c
uint64 sys_wait(void) {
uint64 p;
int nonblock;
if (argaddr(0, &p) < 0||argint(1, &nonblock) < 0) return -1;
return wait(p, nonblock);
}その後、wait関数を変更します。非ブロッキング機能を追加する場合、非ブロッキング待機が呼び出された際にsleep()で待機する前にプロセスロックを解放すれば十分です。これはwait()の実装において子プロセスが存在しない場合の処理方法と同じです。
int wait(uint64 addr, int nonblock) {
//...
// No point waiting if we don't have any children.
if (!havekids || p->killed) {
release(&p->lock);
return -1;
}
// Non block wait
if (nonblock) {
release(&p->lock);
return -1;
}
else
// Wait for a child to exit.
sleep(p, &p->lock); // DOC: wait-sleep
}
}//shell
$ waittest
wait test
no child exited yet, round 0
no child exited yet, round 1
no child exited yet, round 2
proc 4 exit, parent pid 3, name waittest, state sleeping
child exited, pid 4
wait test OK
proc 3 exit, parent pid 2, name sh, state sleeping(3) yieldのデザイン
要求に従い、yieldtestユーザープログラムとyieldシステムコールを登録します。
//kernel/syscall.h
#define SYS_yield 23
//kernel/syscall.c
extern uint64 sys_yield(void);
static uint64 (*syscalls[])(void) = {
//...
[SYS_yield] sys_yield,
};
//user/user.h
int yield(void);
//user/usys.pl
entry("yield")
システムコールが発生するたびに以下の情報を出力する必要があります:
- コンテキストのアドレス範囲(開始アドレス:
&(p->context)、終了アドレス:(void*)&(p->context) + sizeof(p->context))。 - 現在のプロセスの
pidとユーザーモードのプログラムカウンタ(pc値)。
この値はECALL命令を通じてepc状態レジスタに保存され、割り込みフレームに保存されます。 - 次にスケジュールされるプロセスの
pidとそのユーザーモードのpc値。
グローバルプロセステーブル内の次のRUNNABLE状態のプロセスを特定することで、このプロセス情報を取得できます。
uint64 sys_yield(void) {
struct proc *p = myproc(), *p_yield = p;
acquire(&p->lock);
printf("Save the context of the process to the memory region from address %p to %p\n", &(p->context), (void*)&(p->context)+sizeof(p->context));
printf("Current running process pid is %d and user pc is %p\n", p->pid, p->trapframe->epc);
release(&p->lock);
int found = 0;
for (p = proc; p < &proc[NPROC]; p = (++p == &proc[NPROC] ? proc : p)) {
if (p == p_yield) {if(found) break; else found = 1;}
else if (p->state == RUNNABLE && found == 1) {
acquire(&p->lock);
printf("Next runnable process pid is %d and user pc is %p\n", p->pid, p->trapframe->epc);
release(&p->lock);
break;
}
}
yield();
return 0;
}//shell
$ yieldtest
yield test
parent yield
Save the context of the process to the memory region from address 0x0000000080012098 to 0x0000000080012108
Current running process pid is 3 and user pc is 0x0000000000000416
Next runnable process pid is 4 and user pc is 0x0000000000000366
Child with PID 4 begins to run
proc 4 exit, parent pid 3, name yieldtest, state runnable
Child with PID 5 begins to run
proc 5 exit, parent pid 3, name yieldtest, state runnable
Child with PID 6 begins to run
proc 6 exit, parent pid 3, name yieldtest, state runnable
parent yield finished
proc 3 exit, parent pid 2, name sh, state sleepingLab 3 Lock
一、次の質問を答えてなさい
1.メモリアロケータについての質問
2. ディスクキャッシュについての質問
二. コードデザイン
(1) メモリアロケータのデザイン
このタスクの概要は、グローバルメモリアロケータである kmem を複数の部分に分割し、それぞれの部分を各CPUに割り当てることです。言い換えれば、各CPUは独自のメモリアロケータを持つことになります。
各メモリアロケータには、初期化、ページの割当、およびページの解放機能が必要です。
🌟初期化
まず、CPUの数と同じ数の kmem 構造体を定義し、これらが以前のグローバルメモリアロケータを置き換える形にします。そして、kinit() 関数内でそれらを初期化します。ここでは、グローバルバージョンのメモリアロケータの初期化手順を参考にすることができます。最後に、空いているメモリを freerange 関数が呼び出されるCPUに割り当てます。一般的に、これはCPU0であるべきです。このようにすることで、freerange 関数を変更する必要がなくなります。
//kernel/kalloc.c
struct {
struct spinlock lock;
struct run *freelist;
} kmem[NCPU];
void kinit()
{
char s[10];
for(int i = 0; i < NCPU; i++){
snprintf(s, 10, "kmem %d", i); //Lock name with cpuid
initlock(&kmem[i].lock, s);
}
freerange(end, (void*)PHYSTOP); //free mem for a core
}🌟ページの割当
次にkalloc() 。すでにグローバルメモリアロケータは複数の部分に分割されているため、まず、どのCPUがメモリを要求しているかを確認する必要があります。その後、要求されたCPUのメモリ空間からメモリを確保しようと試みます。この間はロックを保持します。もし、CPUが利用可能なメモリ領域を見つけることができたら、そのメモリを割り当て、ロックを解放してメモリを初期化します。このロジックは、グローバルバージョンと完全に同じです。
もし、要求されたCPUの空きページリストに空きがない場合、他のCPUからメモリを奪うことになります。まず、現在保持しているロックを解放し、どのCPUが空きメモリを持っているかをループで確認します。ただし、自分に対する再チェックはスキップします。他のCPUを確認する際には、そのCPUのロックを保持する必要があります。空きメモリが見つかれば、それを割り当てます。もし見つからなければ、次のCPUを確認します。すべてのCPUに空きメモリがなければ、0を返します。
//kernel/kalloc.c
void* kalloc(void)
{
struct run *r;
// cpuid now:
push_off();
int CPUID = cpuid();
pop_off();
// Try to get mem from CPUID space
acquire(&kmem[CPUID].lock);
r = kmem[CPUID].freelist;
if(r){
kmem[CPUID].freelist = r->next;
release(&kmem[CPUID].lock);
memset((char*)r, 5, PGSIZE); // fill with junk
return (void*)r;
}
else {// No space on CPUID, steal
release(&kmem[CPUID].lock);
for(int i = 0; i < NCPU; i++){
if(i==CPUID) continue;
acquire(&kmem[i].lock);
r= kmem[i].freelist;
if(r){
kmem[i].freelist = r->next;
release(&kmem[i].lock);
memset((char*)r, 5, PGSIZE); // fill with junk
return (void*)r;
}
else release(&kmem[i].lock);
}
return 0;
}
}🌟ページの解放kfree() 、実際には、どのCPUが kfree() を呼び出したかを確認し、そのページをそのCPUの空きページリストに追加するだけです。ロジックは、元の kfree() と完全に同じです。
//kernel/kalloc.c
void kfree(void *pa)
{
struct run *r;
if(((uint64)pa % PGSIZE) != 0 || (char*)pa < end || (uint64)pa >= PHYSTOP)
panic("kfree");
// Fill with junk to catch dangling refs.
memset(pa, 1, PGSIZE);
r = (struct run*)pa;
// cpuid now:
push_off();
int CPUID = cpuid();
pop_off();
// free mem:
acquire(&kmem[CPUID].lock);
r->next = kmem[CPUID].freelist;
kmem[CPUID].freelist = r;
release(&kmem[CPUID].lock);
}(2) Buffer Cache のデザイン
このキャッシュは、ハッシュバケットとタイムスタンプを使用して実装されます。
まず、ハッシュバケットを実装し、bcache(キャッシュ)にロックとタイムスタンプ付きのバケットを追加して、LRU(最も長く使われていない)を検索できるようにします。そして、binit() 関数内でそれを初期化します。このロジックは、元のバージョンに似ていますが、キャッシュとキャッシュロックの初期化に加えて、バケットとバケットロックも初期化する必要があります。初期のタイムスタンプには0を。
//kerner/buf.h:struct buf {...
int timestamp;
};
//kernel/bio.c
extern uint ticks;
#define NBUCKET 13
struct {
struct spinlock lock;
struct buf buf[NBUF];
// Linked list of all buffers, through prev/next.
// Sorted by how recently the buffer was used.
// headOfbucket.next is most recent, head.prev is least.
struct buf headOfbucket[NBUCKET]; //Add buckets
struct spinlock lockOf[NBUCKET]; //Add buckets' locks.
} bcache;
void binit(void)
{
struct buf *b;
// INIT bcache
initlock(&bcache.lock, "bcache X"); //bcache lock
char s[10];
for(int i = 0; i < NBUCKET; i++){
snprintf(s, 10, "bcache %d", i); //Lock name with bucketid
initlock(&bcache.lockOf[i], s); //bucket lock
bcache.headOfbucket[i].next = &bcache.headOfbucket[i]; //Ringed Linked List
bcache.headOfbucket[i].prev = &bcache.headOfbucket[i]; //Ringed Linked List
}
//FIRSTLY we should place the blocks to a certain place.
for(int i = 0; i < NBUF; i++){
b = &bcache.buf[i]; //At least 1 cpu:0
initsleeplock(&b->lock, "buffer lk"); //Lock
b->next = bcache.headOfbucket[0].next; //Link After
b->prev = &bcache.headOfbucket[0]; //Link Head
bcache.headOfbucket[0].next->prev = b; //After Link Me
bcache.headOfbucket[0].next = b; //Head Link Me
b->refcnt = 0; //No reference at first
b->timestamp = 0; //0 at beginning
}
// headOfbucket[0]:29->28->...->3->2->1->0->29
// headOfbucket[1]:NULL
// ...
// headOfbucket[12]:NULL
}bget()関数
まず、ブロック番号を計算して得られるハッシュ値をバケット番号として使用して、該当するバケットを検索します。
取得したバケットをロックし、キャッシュヒットを確認する際のアトミック性を確保します。もし検索するブロックがすでにキャッシュされている場合、その参照カウントをインクリメントし、キャッシュブロックをスリープロックでロックします。
//kernel/bio.c
// Part 1 Start
//...
uint hash(uint blockno){return blockno % NBUCKET;}
//...
// Look through buffer cache for block on device dev.
// If not found, allocate a buffer.
// In either case, return locked buffer.
static struct buf* bget(uint dev, uint blockno)
{
struct buf *b;
uint hashval = hash(blockno);
// First, try to find the buffer in the target bucket.
acquire(&bcache.lockOf[hashval]); // Lock the target bucket.
// Is the block already cached?
for(b = bcache.headOfbucket[hashval].next; b != &bcache.headOfbucket[hashval]; b = b->next){
if(b->dev == dev && b->blockno == blockno){
b->refcnt++;
release(&bcache.lockOf[hashval]); // Unlock the bucket.
acquiresleep(&b->lock); // Lock the buffer.
return b;
}
}
//...... Part 1 Endもし、そのバケットにブロックが見つからなかった場合、バケットロックを解放し、LRU戦略を使用して適切なキャッシュブロックを置き換える場所を探します。この時、グローバルロック bcache.lock を取得して、他のプロセスが利用可能なバッファを検索中にキャッシュを変更しないようにします。
LRUの検索はすべてのバケットを対象に行われます。各バケットをロックし、その中のバッファを逆順に辿って、参照カウントが0でタイムスタンプが最小のバッファを探します。もし、あるバケットを検索している最中に、見つかった置換対象のタイムスタンプよりも大きいものがあれば、そのバケット全体をスキップして検索効率を高めます。最終的に置き換え可能なキャッシュブロックが見つかれば、ここで2つのバケットロックを保持することになります。LRUが見つからなかった場合、2つ目のバケットロックはそのループの最後で解放されます。
//...... Part 2 Start
release(&bcache.lockOf[hashval]); // Unlock the bucket.
// Not cached.
// Recycle the least recently used (LRU) unused buffer.
// Acquire global lock to prevent other processes from modifying the cache.
acquire(&bcache.lock);
struct buf *lru_buf = 0;
uint lru_timestamp = 0xFFFFFFFF;
int lru_bucket = -1;
// Search for the LRU buffer.
for(int i = 0; i < NBUCKET; i++){
acquire(&bcache.lockOf[i]); // Lock bucket i.
for(b = bcache.headOfbucket[i].prev; b != &bcache.headOfbucket[i]; b = b->prev){
if(b->timestamp > lru_timestamp)
goto Nextbucket;
if(b->refcnt == 0){
if(b->timestamp < lru_timestamp){
// Found a better LRU buffer.
if(lru_buf != 0 && lru_bucket != hashval && lru_bucket != i){
// Release the previous lru_bucket lock.
release(&bcache.lockOf[lru_bucket]);
}
lru_buf = b;
lru_timestamp = b->timestamp;
lru_bucket = i;
}
}
}
Nextbucket:
if(lru_bucket != i && i != hashval){
// Release bucket i if it's not the lru_bucket or target bucket.
release(&bcache.lockOf[i]);
}
}
if(lru_buf == 0){
if(lru_bucket != -1 && lru_bucket != hashval){
release(&bcache.lockOf[lru_bucket]);
}
release(&bcache.lock);
panic("bget: no buffers");
}
//...... Part 2 End🌟注意
この時点では、キャッシュロックと2つのバケットロックを保持しています。
LRUキャッシュブロックを見つけた後、検索中に他のプロセスがターゲットバケットにブロックをキャッシュしたかどうかを確認します。これは競合状態を回避するためで、2つのプロセスが同じブロック番号に対してキャッシュブロックを割り当てようとする場合を防ぎます。
//...... Part 3 Start
// Now, we hold locks on
// bcache.lock, bcache.lockOf[hashval], and bcache.lockOf[lru_bucket].
// Check whether another process has cached the buffer in the target bucket.
for(b = bcache.headOfbucket[hashval].next; b != &bcache.headOfbucket[hashval]; b = b->next){
if(b->dev == dev && b->blockno == blockno){
b->refcnt++;
if(lru_bucket != hashval)
// Release lru_bucket lock if different.
release(&bcache.lockOf[lru_bucket]);
release(&bcache.lockOf[hashval]); // Release target bucket lock.
release(&bcache.lock); // Release global lock.
acquiresleep(&b->lock); // Lock the buffer.
return b;
}
}
//...... Part 3 Endもし、ブロックが他のプロセスによってキャッシュされていた場合、その偽「LRUバッファ」は破棄され、すでにキャッシュされているブロックが返されます。正しいキャッシュブロックはスリープロックでロックされ、参照カウントが増加します。
他のプロセスがそのブロックをキャッシュしていなければ、LRUバッファを元のバケットから取り除き、ターゲットバケットに挿入します。バケット間の交換により、バッファが正しくハッシュチェーンに配置されます。
//...... Part 4 Start
// Remove lru_buf from its current bucket.
lru_buf->prev->next = lru_buf->next;
lru_buf->next->prev = lru_buf->prev;
// Add lru_buf to the target bucket.
lru_buf->next = bcache.headOfbucket[hashval].next;
lru_buf->prev = &bcache.headOfbucket[hashval];
bcache.headOfbucket[hashval].next->prev = lru_buf;
bcache.headOfbucket[hashval].next = lru_buf;
// Initialize lru_buf.
lru_buf->dev = dev;
lru_buf->blockno = blockno;
lru_buf->valid = 0;
lru_buf->refcnt = 1;
//...... Part 4 Endキャッシュブロックのメタデータを更新した後、すべてのロックを順番に解放します。これにより、プロセス全体のアトミック性が確保されます。その後、スリープロックを使ってキャッシュブロックをロックし、return。
//...... Part 5 Start
// Release locks.
if(lru_bucket != hashval)
release(&bcache.lockOf[lru_bucket]); // Release lru_bucket lock if different.
release(&bcache.lockOf[hashval]); // Release target bucket lock.
release(&bcache.lock); // Release global lock.
acquiresleep(&lru_buf->lock); // Lock the buffer.
return lru_buf;
}
//...... Part 5 Endbrelse 関数では、メモリブロックを解放する際に、グローバル変数 ticks を使ってタイムスタンプを更新する必要があります。
さらに、bpin と bunpin 関数にはハッシュ機能を導入するだけで、その他のロジックの変更はない。
コードは下記に示す通り。
void brelse(struct buf *b)
{
if(!holdingsleep(&b->lock))
panic("brelse");
releasesleep(&b->lock);
uint hashval = hash(b->blockno);
acquire(&bcache.lockOf[hashval]); //Lock the bucket
b->refcnt--;
if (b->refcnt == 0) {
// no one is waiting for it.
b->next->prev = b->prev;
b->prev->next = b->next;
b->next = bcache.headOfbucket[hashval].next;
b->prev = &bcache.headOfbucket[hashval];
bcache.headOfbucket[hashval].next->prev = b;
bcache.headOfbucket[hashval].next = b;
b->timestamp = ticks;
}
release(&bcache.lockOf[hashval]); //Unlock the bucket
}
void bpin(struct buf *b) {
uint hashval = hash(b->blockno);
acquire(&bcache.lockOf[hashval]); //Lock the bucket
b->refcnt++;
release(&bcache.lockOf[hashval]); //Unlock the bucket
}
void bunpin(struct buf *b) {
uint hashval = hash(b->blockno);
acquire(&bcache.lockOf[hashval]); //Lock the bucket
b->refcnt--;
release(&bcache.lockOf[hashval]); //Unlock the bucket
}Lab 4 Page Table
一、次の質問を答えてなさい
ページテーブル機構についての質問
- 1. ページテーブル機構はなぜ発明され、どのような利点があるのか?
-
🌟 なぜページテーブル機構が発明されたのか?
ページテーブル機構は、従来のメモリ管理における断片化、アドレス空間の分離、柔軟性の欠如などの課題を解決するために開発され、コンピュータシステムで仮想メモリを実現するために使用されます。
メモリの断片化を解決するため
連続したメモリ割り当てが外部断片化を引き起こすことがあります。ページテーブルはページング技術を活用し、メモリを固定サイズのページとページフレームに分割することで外部断片化を回避します。
仮想メモリをサポートするため
ページテーブル機構は、使用頻度の低いページをディスクに保存し、必要に応じてメモリにロードすることを可能にします。これにより仮想メモリが拡張され、実行時の必要メモリ空間が物理メモリよりも大幅に大きくなります。
メモリ共有をサポートするため
ページテーブルは非連続的なメモリ割り当てをサポートし、プログラムが連続する物理メモリを使用する必要がなくなります。また、同じ物理ページフレームをマッピングすることで、プロセス間でのメモリ共有を可能にします。🌟 ページテーブル機構の主な利点
メモリ共有とコピーオンライト
読み取り専用データ(例: 共有ライブラリ)を複数のプロセスで共有したり、書き込み時に独立したコピーを作成することで、メモリ使用効率が向上します。
メモリ管理の簡略化
固定サイズのページとページフレームを使った割り当てにより、メモリ管理の複雑さが軽減され、システムの効率が向上します。
仮想アドレスと物理アドレスの変換をサポート
ページテーブルは仮想アドレスと物理アドレスの間のマッピング表として機能し、プログラムが独自の仮想アドレス空間を使用しながら、物理メモリの場所を意識する必要がなくなります。
システムのセキュリティ向上
各プロセスのページテーブルは独立しており、プロセスが他のプロセスのメモリに直接アクセスすることを防ぐことで、システムの安定性とセキュリティを高めます。
オンデマンドページング
ページテーブルを使用することで、ページが実際に使用される際にのみメモリにロードされるため、メモリ使用効率が向上します。 - 2. SV39標準で仮想アドレス0xFFFFFFE789ABCDEFが最終的な物理アドレスになるまでのプロセスを説明なさい。PTEの内容はお好きのままに。
-
 STEP仮想アドレスからExtendedビットを除去
STEP仮想アドレスからExtendedビットを除去SV39では仮想アドレスの高位ビット(Extended部分)は除去されます。
したがって、仮想アドレスは次のようになります:0x6789ABCDEF
バイナリ表現:110 0111 1000 1001 1010 1011 1100 1101 1110 1111STEP上位ページディレクトリエントリの検索SATPレジスタ情報を参照し、仮想アドレスの上位ページディレクトリ番号(
Page Directory Number)を特定します。
番号:110 0111 10=0x19E
上位ページディレクトリから該当するエントリを検索し、ある物理アドレスを取得します、例えば0x0000011B78A000。STEP中位ページディレクトリエントリの検索中位のページディレクトリ番号は以下の通りです:
00 1001 101=0x04D
中位ページディレクトリから該当するエントリを検索し、物理アドレスを取得します:0x0000011A799000。STEP下位ページテーブルエントリの検索下位のページテーブル番号は以下の通りです:
0 1011 1100=0x0BC
下位ページテーブルから該当するエントリを検索し、物理フレームIDを取得します:0x00000000E83。STEPオフセットを加算して物理アドレスを取得オフセット部分は以下の通りです:
1101 1110 1111=0xDEF
最終的な物理アドレスは次の通りです:0x00000000E83DEF - 3. SV39標準における仮想アドレスのL2、L1、L0がそれぞれ9ビットであるのは設計上の必然です。それらが9ビットでなければならず、10ビットや8ビットにできない理由を説明します(ヒント:ページディレクトリのサイズはページサイズと同じである必要があります)。
-
SV39では、1つのPage Table Entryは64ビット(8バイト)です。一般的に1ページのサイズは4KB(4096バイト)です。1ページに格納できるPage Table Entryの最大数は次のように計算されます: $\frac{4096 \, \text{bytes}}{8 \, \text{bytes/entry}} = 512 \, \text{entries}$ 512エントリは、ビット数で表すと $\log_2 512 = 9$ です。
10ビットや8ビットではない理由
10ビットの場合:
1つのページテーブルが最大1024エントリを指せることになりますが、これはページサイズを超えるため不可能です。
8ビットの場合:
最大256エントリしか格納できず、ページサイズの半分が無駄になります。
そのため、最大限効率的な9ビットが選ばれています。 - 4. SV39の「39」が何を意味するかはすでに理解しています。しかし、もう一つの仮想アドレスの規格であるSV48というものがあります。これは、3階層のページテーブルを使用するSV39とは異なり、4階層のページテーブルを採用しています。SV39の模式図を参考にしながら、SV48のページテーブルのデータ構造とアドレス変換フローを示す模式図を作成できますか?
-

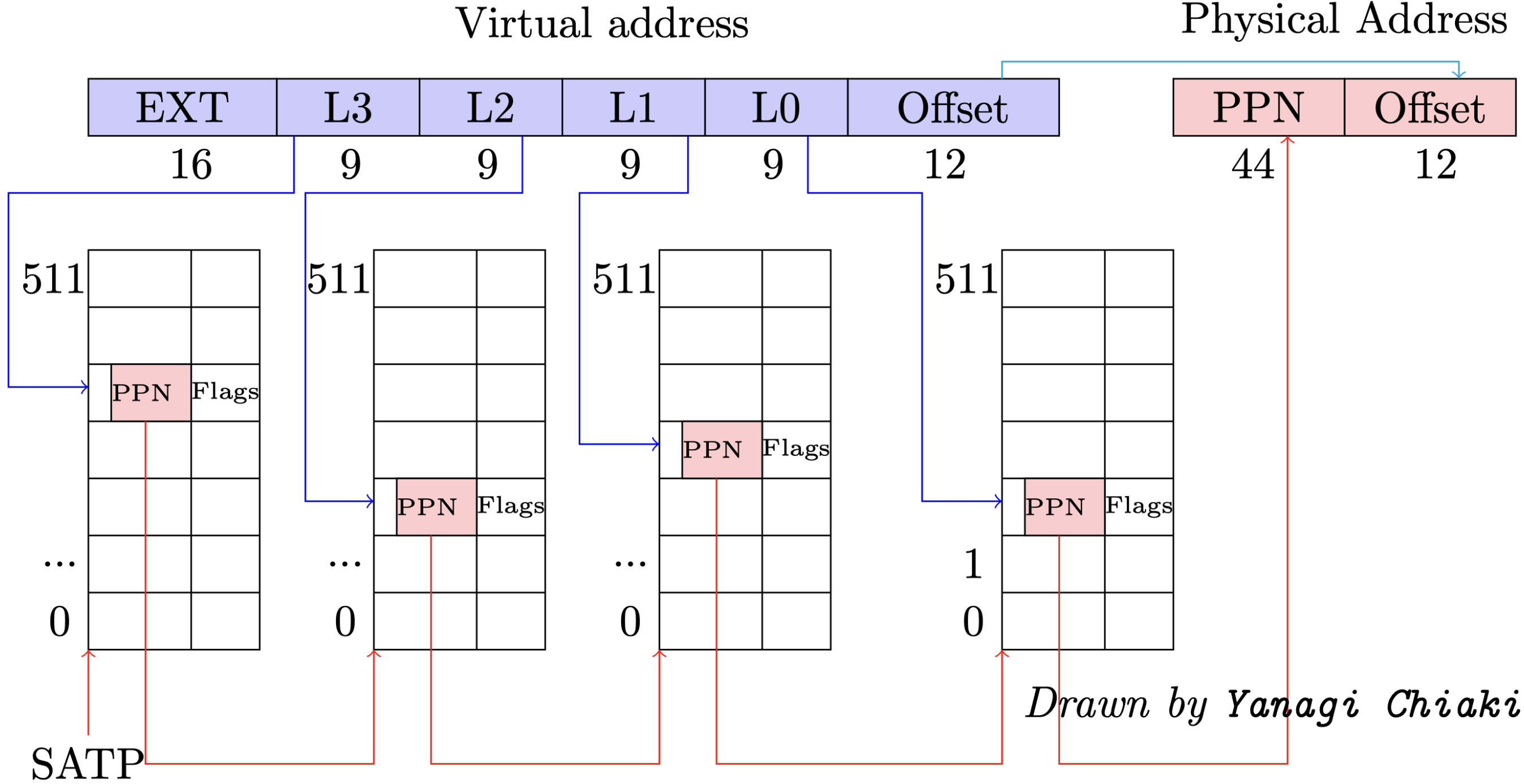
二. コードデザイン
(1) ページテーブルの出力
このタスクを実現するために、以下の2つの補助関数を設計しました。
1つ目は文字列結合関数 concat、もう1つはページの権限フラグ情報を出力する関数 PTE2STRです。
void concat(char r[], char a[], char b[]) {
int i = 0, j = 0;
for (i = 0; a[i] != '\0'; i++) r[i] = a[i];
for (j = 0; b[j] != '\0'; j++) r[i + j] = b[j];
r[i + j] = '\0';
}
char* PTE2STR(pte_t PTE) {
static char flagstr[5] = "----";
flagstr[0] = (PTE & PTE_R) ? 'r' : '-';
flagstr[1] = (PTE & PTE_W) ? 'w' : '-';
flagstr[2] = (PTE & PTE_X) ? 'x' : '-';
flagstr[3] = (PTE & PTE_U) ? 'u' : '-';
return flagstr;
}concatは文字列を結合するだけの簡単な関数なので、詳細は割愛します。PTE2STRは、PTE内の4つのフラグを確認し、該当ビットが1の場合に対応する権限があることを出力します。
ページテーブルの逐次出力
ページテーブルを段階的に出力する必要があるため、再帰的に処理を行う関数vmprint_levelを考え。この関数は、freewalkのコードを参考にし、ページテーブルを走査するロジックを取り入れています。ページを指定すると、その512個のPTEを走査して情報を取得できます。
再帰ロジックの具体的な手順
- 現在のページテーブルの512個のエントリを走査する
各エントリ(PTE)の有効ビット(PTE_V)を確認します。 - 次のレベルのページテーブルを指している場合
PTEにPTE_R | PTE_W | PTE_X権限がない場合、そのPTEは次のページテーブルを指しているとみなされます。このとき、PTE2PA()を使用して次のレベルのページテーブルの物理アドレスを取得し、指している情報とフラグを出力します。その後、その物理ページに対して再帰的にvmprint_levelを呼び出し、さらに深いレベルの内容を処理します。このとき、仮想アドレスは現在の基準から9ビット左シフトされます。 - 物理ページを指している場合
PTEにPTE_R | PTE_W | PTE_Xのいずれかの権限がある場合、そのPTEは物理ページを指しています。この場合、仮想アドレスは(bvaddr + i) << 12(下位ビットを0で埋めてページ境界に揃える)で計算され、仮想アドレスから物理アドレスへのマッピングが出力されます。最後にフラグを出力します。
void
vmprint_level(pagetable_t pagetable, char* bars, int level, uint64 bvaddr)
{
if(level>3) return;
for(int i = 0; i < 512; i++){
pte_t pte = pagetable[i];
if(pte & PTE_V){
if((pte & (PTE_R|PTE_W|PTE_X)) == 0){
// this PTE points to a lower-level page table.
uint64 child = PTE2PA(pte);
printf("%sidx: %d: pa: %p, flags: %s\n", bars, i, PTE2PA(pte), PTE2STR(pte));
char d[10];
concat(d, dots," ||");
vmprint_level((pagetable_t)child, d, level + 1, (bvaddr+i) << 9);
} else {
printf("%sidx: %d: va: %p -> pa: %p, flags: %s\n", bars, i, (bvaddr+i)<<12, PTE2PA(pte), PTE2STR(pte));
}
}
}
}出力フォーマット
階層構造を表現する||記号は文字列結合操作で実現しています。この部分のフォーマットは比較的単純なので、詳細は省略します。
以下は、vmprint_level関数を実装する関数。
void vmprint(pagetable_t pagetable){
printf("page table %p\n", pagetable);
// there are 2^9 = 512 PTEs in a page table.
vmprint_level(pagetable, "||", 1, 0);
}(2) プロセス専用のカーネルページテーブル
本タスクの目標は以下の通りです:各プロセスが独自のカーネルページテーブルを持つようにすることです。これにより、カーネルがユーザースペースのポインタにアクセスする際、追加の物理アドレス変換を行わずに直接デリファレンスできるようになります。
各プロセスに独自のカーネルページテーブルを持たせるためには、ページテーブルの参照をプロセス制御ブロック(PCB)に組み込むことが自然なアプローチとして考えられます。
//kernel/proc.h
struct proc {
//...
pagetable_t pagetable; // User page table
pagetable_t kernel_pagetable;
//...参照を設定した後、allocprocでプロセスの初期化時にこの参照が指すカーネルページテーブルを設定することを検討します。この際、ユーザーページテーブルの参照設定を実装する方法を参考にします。
カーネルページテーブルをOSレベルからプロセスレベルに移行するにあたり、カーネルスタックのマッピングも再設計する必要があります。従来のロジックでは、OS(procinit)が64個のプロセス用のカーネルスタック位置を直接設定しており、その間をガードページで分離して境界超過を防いでいました。しかし、カーネルページテーブルが共有されなくなるため、カーネルスタックの割り当てをプロセス初期化時に行う必要があります。このため、関連コードをその箇所に移動するだけで対応できます。
//kernel/proc.c:allocproc{...
// An empty user page table.
p->pagetable = proc_pagetable(p);
if(p->pagetable == 0){
freeproc(p);
release(&p->lock);
return 0;
}
p->kernel_pagetable = ukvminit();
if(p->kernel_pagetable == 0){
freeproc(p);
release(&p->lock);
return 0;
}
char *pa = kalloc();
if(pa == 0)
panic("kalloc");
uint64 va = KSTACK((int) (p - proc));
mappages(p->kernel_pagetable, va, PGSIZE, (uint64)pa, PTE_R | PTE_W);
p->kstack = va;
//...}以上のタスクを完了した後、カーネルページテーブルのライフサイクルに注目:作成、使用、解放。
作成については、共有カーネルページテーブルを作成する方法(kvminit)を参考にします。従来のカーネルページテーブルは全プロセスで共有されていたため、一部の詳細を調整する必要があります。例えば、kvmmapを使い続けることはできません。これはOSの実行中に一度しか使用できないためです。この箇所では通常のmappagesを使用し、引数の値は変更しなくても問題ありません。ただし、CLINTのマッピングを無効化する必要があります。これはCLINTがPLICの下に位置しているためです。この対応を怠ると、タスク3を完了する際に問題が発生します。
//kernel/vm.c
pagetable_t
ukvminit()
{
pagetable_t ukernel_pagetable = uvmcreate();
memset(ukernel_pagetable, 0, PGSIZE);
// uart registers
mappages(ukernel_pagetable, UART0, PGSIZE, UART0, PTE_R | PTE_W);
// virtio mmio disk interface
mappages(ukernel_pagetable, VIRTIO0, PGSIZE, VIRTIO0, PTE_R | PTE_W);
// CLINT
//mappages(ukernel_pagetable, CLINT, 0x10000, CLINT, PTE_R | PTE_W);
// PLIC
mappages(ukernel_pagetable, PLIC, 0x400000, PLIC, PTE_R | PTE_W);
// map kernel text executable and read-only.
mappages(ukernel_pagetable, KERNBASE, (uint64)etext-KERNBASE, KERNBASE, PTE_R | PTE_X);
// map kernel data and the physical RAM we'll make use of.
mappages(ukernel_pagetable, (uint64)etext, PHYSTOP-(uint64)etext, (uint64)etext, PTE_R | PTE_W);
// map the trampoline for trap entry/exit to
// the highest virtual address in the kernel.
mappages(ukernel_pagetable, TRAMPOLINE, PGSIZE, (uint64)trampoline, PTE_R | PTE_X);
return ukernel_pagetable;
}使用に関しては、プロセス切り替え時に対応するカーネルページテーブルを切り替える必要があります。スケジューラ内でプログラムを切り替える前に、カーネルページテーブルを切り替える実装を行います。オリジナル版(2020年版)xv6の実験を参考にし、プロセスが存在しない場合には共有メモリのページテーブルに戻す必要があります。
//kernel/proc.c
extern pagetable_t kernel_pagetable;
void
scheduler(void)
{
//...
p->state = RUNNING;
c->proc = p;
w_satp(MAKE_SATP(p->kernel_pagetable));
sfence_vma();
swtch(&c->context, &p->context);
kvminithart();
//...
#if !defined (LAB_FS)
if(found == 0) {
w_satp(MAKE_SATP(kernel_pagetable));
sfence_vma();
intr_on();
asm volatile("wfi");
}
#else
;
#endif
}
}解放に関しては、プロセスが終了した場合、そのプロセスに紐づくカーネルページテーブルとカーネルスタックを解放する必要があります。これを行わないとメモリリークが発生します。解放の際にはページテーブルを再帰的に解放することを注意しますが、ページテーブルのリーフにある物理ページを解放しないようにします。これを怠るとカーネルがクラッシュする原因になります。freewalk関数を参考にしてこの機能を実装します。最後にfreeproc内でこの関数を呼び出し、カーネルページテーブルとカーネルスタックを削除すれば完了です。
//kernel/proc.c
//Free the table but keep the mem alive
void
proc_freekernelpagetable(pagetable_t pagetable)
{
// there are $2^9$ = 512 PTEs in a page table.
for(int i = 0; i < 512; i++){
pte_t pte = pagetable[i];
if((pte & PTE_V) && (pte & (PTE_R|PTE_W|PTE_X)) == 0){
// this PTE points to a lower-level page table.
uint64 child = PTE2PA(pte);
proc_freekernelpagetable((pagetable_t)child);
pagetable[i] = 0;
}
}
kfree((void*)pagetable);
}
//kernel/proc.c:freeproc()\{...
if(p->kernel_pagetable) {
uvmunmap(p->kernel_pagetable, p->kstack, 1, 1); //p->kstack no mono wo free suru
proc_freekernelpagetable(p->kernel_pagetable);
}
p->kernel_pagetable = 0;
}(3) copyin/copyinstr の簡素化
本タスクの目的は、ユーザーページテーブル上の内容をカーネルページテーブルに同期させることです。
uvmcopy関数がこの目的に適した修正ポイントとなります。この関数を利用して、ユーザーページテーブル上のマッピング関係をカーネルページテーブルに統合することが可能です。同期して統合する機能がある以上、同期して解除する機能も設計する必要があります。この際、uvmdealloc関数を参考にして実装します。
特に、上記の統合および解除は重複するマッピングを扱うものであるため、これらのコード実装において物理メモリを誤って操作しないように注意が必要です。
//kernel/vm.c
int
uvmcopy_k(pagetable_t user_pt, pagetable_t kernel_pt, uint64 start, uint64 sz)
{
pte_t *pte;
uint64 pa, i;
uint flags;
for(i = PGROUNDUP(start); i < start + sz; i += PGSIZE){
if((pte = walk(user_pt, i, 0)) == 0)
panic("uvmcopy_k: pte should exist");
if((*pte & PTE_V) == 0)
panic("uvmcopy_k: page not present");
pa = PTE2PA(*pte);
flags = PTE_FLAGS(*pte);
if(mappages(kernel_pt, i, PGSIZE, (uint64)pa, flags & ~PTE_U) != 0) //clear U
goto err;
}
return 0;
err:
uvmunmap(kernel_pt, 0, (i-start) / PGSIZE, 0);//No physical mem removal
return -1;
}
uint64
uvmdealloc_k(pagetable_t pagetable, uint64 oldsz, uint64 newsz)
{
if(newsz >= oldsz)
return oldsz;
if(PGROUNDUP(newsz) < PGROUNDUP(oldsz)){
int npages = (PGROUNDUP(oldsz) - PGROUNDUP(newsz)) / PGSIZE;
uvmunmap(pagetable, PGROUNDUP(newsz), npages, 0);
}
return newsz;
}
uvmcopyを参考にする場合、ページの割り当てやページのクリアに関するコードを削除する必要があります。また、PTEをコピーする際には、カーネルページテーブルはPTE_Uフラグが付与されたページにアクセスできないため、このフラグを消去する必要があります。カーネルページテーブルがこれらのページにアクセスできるようにするためです。
uvmdeallocを参考にする場合、内部で使用されるuvmunmap呼び出しの調整が必要です。物理ページを解放しないように修正します。
2つの関数を完成させた後は、必要な箇所で適切に呼び出しを追加するだけです。ここで必要な箇所とは、ユーザーページテーブルが変更される全ての箇所を指します。コードを確認した結果、以下の箇所で変更が必要です:userinit、fork、growproc、exec。uvmcopy_kとuvmdealloc_kの使用方法はオリジナル版に非常に似ているため、同様の方法で呼び出すだけで問題ありません。以下のコードを見れば分かる通り、基本的にコピー&ペースト作業になるため、詳細な説明はここで割愛。
//kernel/proc.c
void
userinit(void)
{
//...
uvminit(p->pagetable, initcode, sizeof(initcode));
uvmcopy_k(p->pagetable, p->kernel_pagetable, 0, PGSIZE);
//...
}
int
fork(void)
{
//...
// Copy user memory from parent to child.
if(uvmcopy(p->pagetable, np->pagetable, p->sz) < 0){
freeproc(np);
release(&np->lock);
return -1;
}
np->sz = p->sz;
if(uvmcopy_k(np->pagetable,np->kernel_pagetable,0 , np->sz) < 0){
freeproc(np);
release(&np->lock);
return -1;
}
//...}
int
growproc(int n)
{
//...
if(n > 0){
if((sz = uvmalloc(p->pagetable, sz, sz + n)) == 0) {
return -1;
}
if(uvmcopy_k(p->pagetable,p->kernel_pagetable, p->sz, n) < 0) {
return -1;
}
} else if(n < 0){
uvmdealloc(p->pagetable, sz, sz + n);
sz = uvmdealloc_k(p->kernel_pagetable, sz, sz + n);
}
p->sz = sz;
return 0;
}
//kernel/exec.c:exec(){...
// Commit to the user image.
oldpagetable = p->pagetable;
p->pagetable = pagetable;
p->sz = sz;
p->trapframe->epc = elf.entry; // initial program counter = main
p->trapframe->sp = sp; // initial stack pointer
proc_freepagetable(oldpagetable, oldsz);
uvmunmap(p->kernel_pagetable, 0, oldsz/PGSIZE, 0);
uvmcopy_k(p->pagetable, p->kernel_pagetable, 0, p->sz);
if(p->pid==1) vmprint(p->pagetable);
return argc; // this ends up in a0, the first argument to main(argc, argv)
//...
}ユーザーページテーブルとカーネルページテーブルの互換性を確保するためには、ユーザープログラムのアドレスがPLICを超えないように制限する必要があります。この制限はuvmalloc内で実現します。
//kernel/vm.c
uint64
uvmalloc(pagetable_t pagetable, uint64 oldsz, uint64 newsz)
{
char *mem;
uint64 a;
if(newsz < oldsz)
return oldsz;
if(newsz >= PLIC)
return 0;
//...}最後は、kvmpaでカーネルページテーブルが使用されている。ここでは、カーネルページテーブルがプロセス専用であるため、walk呼び出しの引数を調整してこの問題に対応してでいい。
//kernel/vm.c
uint64
kvmpa(uint64 va)
{
uint64 off = va % PGSIZE;
pte_t *pte;
uint64 pa;
pte = walk(myproc()->kernel_pagetable, va, 0);
if(pte == 0)
panic("kvmpa");
if((*pte & PTE_V) == 0)
panic("kvmpa");
pa = PTE2PA(*pte);
return pa+off;
}Lab 5 File System
以上です

コメント